Alla fine di un’intervista personalizzata di due ore con un individuo, i ricercatori documentano un modello di intelligenza artificiale che ricostruisce la sua personalità, anticipando le sue reazioni e le sue opinioni su argomenti di discussione.
Pubblicato
Tempo di lettura : 3min
I ricercatori sviluppano gemelli digitali, con intelligenze artificiali che clonerebbero la nostra personalità. (Illustrazione) (JONATHAN KNOWLES / STONE RF / GETTY IMAGES)
Eravamo abituati a sentire parlare di anime gemelle, ora i ricercatori stanno sviluppando gemelli digitali, con intelligenze artificiali che clonerebbero la nostra personalità.
Ancora una volta, quando si tratta di intelligenza artificiale, la questione fondamentale riguarda i dati utilizzati per addestrare il modello algoritmico. Sono questi dati che contribuiranno alle performance dei risultati ottenuti. Ricercatori dell’Università di Stanford negli Stati Uniti, insieme ai team dell’entità IA di Alphabet, Google DeepMind hanno pubblicato alla fine del 2024 uno studio volto a creare repliche della personalità di individui del tutto ordinari.
Il tutto inizia con la redazione di un questionario molto personale. Il soggetto risponde a domande su ricordi significativi, momenti chiave della sua infanzia, le tappe del suo percorso professionale, le sue opinioni su temi di società… In due ore, si tratta di raccogliere il massimo di elementi che hanno contribuito a formare la persona che è oggi. Gli scienziati hanno così interpellato circa mille persone con una moltitudine di criteri diversi: età, livello di istruzione, origine regionale, appartenenza politica…
Gli esperti sono categorici: non c’è niente di meglio degli incontri faccia a faccia per ottenere più informazioni di valore rispetto alla presentazione di un modulo digitalizzato. Questa fase molto umana sembra determinante nella qualità dei dati così raccolti.
I test effettuati mostrano quindi una corrispondenza dell’85% tra le risposte fornite dai cloni e il loro originale umano, a una serie di esami: giochi di logica, sondaggi su fatti sociali, test di personalità… Ovviamente, questa meccanica è ancora imperfetta per punti di vista concettuali o filosofici elaborati. Qui, il profiling sperimentale rimane piuttosto basilare. E questo richiederebbe mezzi tecnici molto importanti, se si volesse impiegare l’uso al di là di questo esercizio scientifico.
Tuttavia, questo illustra la capacità di avvicinarsi ai meccanismi del ragionamento umano. Con ovviamente dei rischi riguardo usi devianti per usurpare identità, se si combinasse questa tecnologia con i deepfake che imitano l’immagine o la gestualità in video.
Da ottobre 2022, con ChatPlusITALIA conosciamo l’IA generativa che permette di creare immagini, testi, suoni o video. Qui, si parla di IA agentica. Questi “agenti” non eseguiranno un solo compito, come redigere un paragrafo, ma completeranno una successione di azioni.
Come per esempio quando gli chiederete di scrivere un’email, dopo aver fatto il resoconto della riunione, e verificato negli agenda la disponibilità delle persone per la prossima sessione. Si tratta di decomporre un’azione complessa in una serie di sequenze semplici. Con applicazioni che sicuramente si moltiplicheranno nel 2025!
Di solito, quando un’azienda di software rilascia una nuova versione principale a maggio, non cerca di affiancarla con un’altra versione principale quattro mesi dopo. Ma il ritmo dell’innovazione nel campo dell’IA generativa è tutt’altro che normale.
Sebbene OpenAI abbia lanciato il suo nuovo modello GPT-4o a metà maggio, l’azienda non si è fermata. Già a novembre scorso, Reuters ha diffuso una voce secondo cui OpenAI stava lavorando a un modello linguistico di nuova generazione, allora conosciuto con il nome di Q*. Questa voce è stata confermata a maggio, indicando che Q* era in fase di sviluppo con il nome in codice Strawberry.
Si scopre che Strawberry è in realtà un modello chiamato o1-preview, ora disponibile come opzione per gli abbonati a ChatPlus Plus. Puoi selezionare il modello dal menu a tendina:
Screenshot di David Gewirtz/ZDNET
Scomporre domande e problemi in fasi
Come potete immaginare, se un nuovo modello di ChatPlus è disponibile, lo metterò alla prova. Ed è proprio quello che sto facendo qui.
Il nuovo modello Strawberry si concentra sul ragionamento, scomponendo le domande e i problemi in fasi. OpenAI presenta questa metodologia attraverso un riepilogo del ragionamento, che può essere mostrato prima di ogni risposta.
Quando viene posta una domanda a o1-preview, il modello elabora il ragionamento e poi mostra il tempo impiegato per arrivare a una soluzione. Se apri la lista a tendina, vedrai un riepilogo del ragionamento. Ecco un esempio tratto da uno dei miei test di programmazione:
Screenshot di David Gewirtz/ZDNET
Il modello o1-preview fornisce numerose spiegazioni sul codice
È positivo che l’IA abbia saputo abbastanza da includere la gestione degli errori. Trovo interessante che o1-preview classifichi questa fase nella categoria “Conformità normativa”.
Ho anche scoperto che il modello o1-preview fornisce spiegazioni molto dettagliate sul codice. Durante il mio primo test, che consisteva nella creazione di un plugin per WordPress, il modello ha fornito spiegazioni sull’header, sulla struttura delle classi, sul menu di amministrazione, sulla pagina di amministrazione, sulla logica, sulle misure di sicurezza, sulla compatibilità, sulle istruzioni per l’installazione, sull’uso e persino sui dati di test. Molte più informazioni rispetto ai modelli precedenti.
Ma, in realtà, la prova del nove è nei fatti. Mettiamo questo nuovo modello alla prova con i nostri test standard e vediamo se funziona bene.
Scrivere un plugin WordPress
Questo semplice test di codifica richiede una conoscenza del linguaggio di programmazione PHP e del framework WordPress. La sfida chiede all’IA di scrivere sia un codice per l’interfaccia che una logica funzionale, con la particolarità che, invece di eliminare le voci duplicate, deve separarle, in modo che non siano adiacenti.
Il modello o1-preview ha eccelso. Ha inizialmente presentato l’interfaccia utente sotto forma di un semplice campo di input:
Screenshot di David Gewirtz/ZDNET
Una volta inseriti i dati e cliccato su “Randomize Lines”, l’IA ha generato un campo di output con i dati correttamente randomizzati. Si può notare che Abigail Williams è duplicata e, come richiesto dalle istruzioni del test, le due occorrenze non sono elencate una accanto all’altra:
Screenshot di David Gewirtz/ZDNET
Nei miei test di altri LLM, solo quattro dei dieci modelli hanno superato questo test. Il modello o1-preview ha superato perfettamente questa prova.
2. Riscrittura di una funzione di stringa
Il nostro secondo test corregge una regex (espressione regolare) per stringhe che conteneva un bug segnalato da un utente. Il codice originale era progettato per verificare se un numero inserito fosse valido per dollari e centesimi. Sfortunatamente, il codice accettava solo numeri interi (quindi 5 era valido, ma non 5,25).
Il modello o1-preview ha riscritto il codice con successo. Il modello si è unito a quattro dei miei precedenti test LLM nel gruppo dei vincitori.
3. Scoperta di un bug fastidioso
Questo test è stato creato da un bug reale che ho avuto difficoltà a risolvere. L’identificazione della causa principale richiedeva una conoscenza del linguaggio di programmazione (in questo caso, PHP) e delle sfumature dell’API di WordPress.
I messaggi di errore forniti non erano tecnicamente corretti. I messaggi di errore facevano riferimento all’inizio e alla fine della sequenza di chiamate che stavo eseguendo, ma il bug era legato alla parte centrale del codice.
Non ero l’unico a sforzarmi per risolvere il problema. Tre degli altri LLM che ho testato non sono riusciti a identificare la causa principale del problema e hanno consigliato la soluzione più ovvia (ma errata) di modificare l’inizio e la fine della sequenza di chiamate.
Il modello o1-preview ha fornito la soluzione corretta. Nella sua spiegazione, il modello ha anche indicato la documentazione dell’API di WordPress per le funzioni che avevo utilizzato in modo errato. Questo ha fornito una risorsa aggiuntiva per imparare il motivo della sua raccomandazione. Molto utile.
4. Scrivere uno script
Questa sfida richiede che l’IA integri conoscenze in tre sfere di programmazione distinte:
Il linguaggio AppleScript
Il DOM di Chrome (la struttura interna di una pagina web)
Keyboard Maestro (uno strumento di programmazione specializzato)
Per risolvere questa questione, è necessario comprendere queste tre tecnologie e il modo in cui devono lavorare insieme.
Ancora una volta, o1-preview ha superato il test, unendosi a soli tre degli altri dieci LLM che hanno risolto questo problema.
Un chatbot molto loquace
La nuova approccio al ragionamento di o1-preview non diminuisce quindi la capacità di ChatPlus di superare i nostri test di programmazione. Il risultato del mio primo test sul plugin di WordPress, in particolare, sembra funzionare come un software più sofisticato rispetto alle versioni precedenti.
È positivo che ChatPlus fornisca fasi di ragionamento all’inizio del suo lavoro e dati esplicativi alla fine. Tuttavia, le spiegazioni possono essere lunghe. Ho chiesto a o1-preview di scrivere “Hello world” in C#, la linea di test canonica nella programmazione. Ecco come ha risposto GPT-4o:
Screenshot di David Gewirtz/ZDNET
Ecco come o1-preview ha risposto allo stesso test:
Screenshot di David Gewirtz/ZDNET
È un bel po’. Puoi anche aprire il menu a tendina del ragionamento per ottenere ulteriori informazioni:
Screenshot di David Gewirtz/ZDNET
Tutte queste informazioni sono eccellenti. Ma è un bel po’ di testo da filtrare. Preferisco una spiegazione concisa, con opzioni per ulteriori informazioni in menu a tendina.
Tuttavia, il modello o1-preview di ChatPlus ha dato risultati eccellenti. Non vedo l’ora di vedere come funzionerà quando sarà integrato in modo più completo con le funzionalità di GPT-4o, come l’analisi dei file e l’accesso al Web.
Hai provato a programmare con o1-preview? Quali sono state le tue esperienze? Facci sapere nei commenti qui sotto.
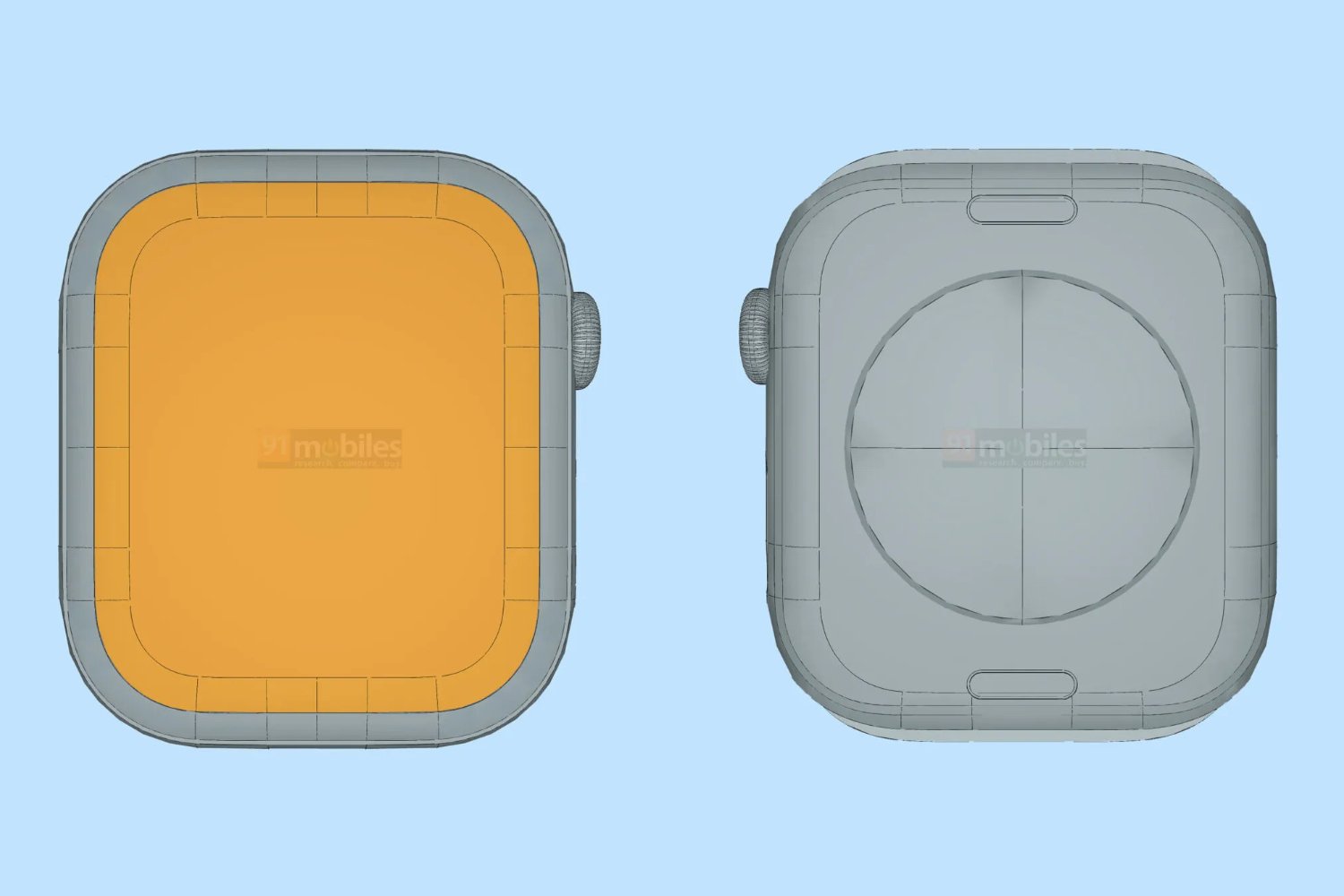
Apple svelerà le novità il lunedì 9 settembre, con l’evento “Luce sul Futuro”, che sarà l’occasione per presentare nuovi prodotti: gli iPhone 16, probabilmente nuovi AirPods e anche nuove Apple Watch. Questa edizione annuale di orologi smart sarà particolarmente speciale, essendo l’anniversario.Quindi, lunedì prossimo, alle 19:00 ora di Parigi, Apple svelerà le sue novità per la fine dell’anno. Come al solito, i protagonisti saranno gli iPhone. Si sa già molto sull’iPhone 16, e il produttore non si fermerà qui. Si aspettano anche nuovi AirPods e Apple Watch.
Nuovo design per l’Apple Watch Series 10
Per quanto riguarda gli orologi smart, Mark Gurman preannuncia grandi novità nel suo riepilogo pre-keynote: tutti i modelli avranno una nuova generazione. Sarà il caso dell’Apple Watch SE (3a generazione), dell’Apple Watch Ultra 3 e dell’Apple Watch Series 10. I cambiamenti più significativi riguarderanno infatti la Series 10, che celebrerà i 10 anni dalla presentazione del primo Apple Watch, nel 2014 (la commercializzazione vera e propria è iniziata nella primavera del 2015).
L’investigatore di Bloomberg “conferma” – se così si può dire – le voci precedentemente ascoltate sulla futura Series 10. Gli schermi dovrebbero essere più grandi e il telaio più sottile, e questo sarà visibile secondo Gurman. Un nuovo design, quindi, anche se le forme rimarranno globalmente le stesse: non si cambia una formula vincente da 10 anni.
2. La rilevazione dell’apnea notturna
Una grande novità per la salute dovrebbe fare il suo debutto: la rilevazione dell’apnea notturna. Questo disturbo respiratorio si verifica durante il sonno ed è caratterizzato da pause involontarie nella respirazione che possono durare da pochi secondi a diversi minuti. Questo disturbo, i cui sintomi includono ronzii forti, risvegli frequenti e una sensazione di soffocamento, può aumentare il rischio di malattie cardiovascolari, ipertensione e diabete.
Gurman avverte, tuttavia, che questa funzione (che si basa sul monitoraggio del sonno dell’Apple Watch) potrebbe non essere disponibile subito al lancio della Series 10. Per quanto riguarda la funzione di rilevazione della pressione sanguigna, annunciata da anni dai rumors, sembra essere stata ancora una volta rimandata a tempi migliori.
Il destino del sensore SpO2 (livello di ossigeno nel sangue) è ancora incerto. Non si sa se sarà nuovamente operativo e fisicamente presente nei nuovi orologi. Almeno negli Stati Uniti, dove il produttore Masimo ha ottenuto un divieto di vendita delle Apple Watch con questo sensore. Il resto del mondo, dove la funzione SpO2 è ancora disponibile, ne sarà privato a sua volta?
3. Maggiore resistenza all’acqua
L’Apple Watch Series 10 potrebbe integrare l’app Profondità, secondo fonti di 9to5Mac. Questa app, come suggerisce il nome, consente di misurare la profondità (fino a 40 metri) durante un’attività subacquea ed è attualmente un’esclusiva dell’Apple Watch Ultra. E non è sorprendente: l’orologio multiuso funge anche da computer da immersione. Può persino essere immerso fino a 100 metri.
La presenza di questa app indica che la Series 10 sarà dotata di una migliore resistenza all’acqua. Gli attuali modelli possono essere immersi fino a 50 metri, ma il loro utilizzo non è consigliato per attività sportive come le immersioni subacquee.
4. Apple Intelligence per un coach salute?
Le funzioni di IA generativa di Apple rimangono limitate a iPhone, iPad e Mac. HomePod, Apple TV, Vision Pro e Apple Watch ne sono privi! E per quanto riguarda gli orologi, non ci saranno cambiamenti lunedì. Tuttavia, Apple Intelligence dovrebbe essere al centro del futuro servizio di coach salute dell’azienda, secondo Gurman.
Questo coach offrirebbe consigli su come mangiare più sano, fare esercizio e dormire meglio, basandosi sui dati raccolti dall’Apple Watch (frequenza cardiaca, attività fisica, cicli del sonno, ecc.). Probabilmente entrerà a far parte dei servizi a pagamento di Apple. Approfitterà l’azienda della keynote della prossima settimana per svelare le linee guida principali di questo nuovo servizio?
Gli utenti di Firefox alla ricerca di un modo rapido per sfruttare l’IA generativa possono ora farlo senza nemmeno lasciare la pagina corrente del loro browser.
La funzionalità di IA fa parte di una nuova pagina, Firefox Labs, all’interno dello schermo delle impostazioni, che permette di provare funzioni sperimentali sviluppate dai cervelli di Mozilla.
Come provare il chatbot integrato nella tua barra laterale?
Per provarla, assicurati di utilizzare la versione 130 o successiva di Firefox. Per verificarlo:
Clicca sull’icona con tre linee in alto a destra
Seleziona Aiuto, poi clicca su Informazioni su Firefox
Il browser scaricherà e installerà automaticamente l’ultima versione
Da lì:
Clicca sull’icona con tre linee
Seleziona Impostazioni
Poi clicca sulla nuova opzione per Firefox Labs
Spunta la casella Chatbot AI
Clicca sul menu a discesa per scegliere tra Anthropic Claude, ChatPlus di OpenAI, Google Gemini, HuggingChat e Le Chat Mistral.
Avrai bisogno di un account per il chatbot
Per chi non conosce questi ultimi due nomi, HuggingChat è un’alternativa open-source a ChatPlus, mentre Le Chat Mistral è uno strumento di IA francese attualmente in versione beta.
Una volta selezionato il tuo chatbot preferito, esso apparirà nella barra laterale a sinistra, dove potrai inviare richieste e avviare conversazioni.
Avrai bisogno di un account per il chatbot che hai scelto prima di poter accedere tramite Firefox.
Possibilità di selezionare direttamente il testo
Se non sei già connesso al sito web dell’IA, ti verrà chiesto di effettuare il login. Puoi facilmente chiudere la barra laterale quando non ne hai bisogno e riaprirla cliccando sull’icona della barra laterale nella barra degli strumenti superiore.
Screenshot di Lance Whitney/ZDNET
Oltre a conversare con l’IA tramite la barra laterale, puoi chiederle di aiutarti a selezionare del testo. Per fare ciò:
Assicurati che l’opzione “Mostra suggerimenti alla selezione del testo” sia selezionata
Seleziona il testo sulla pagina web esistente, poi clicca sulla piccola stella che appare
Si apre un menu con opzioni come Riassumere e Semplificare il linguaggio
Scegli l’opzione che preferisci e l’IA farà del suo meglio per riassumere o semplificare il testo selezionato
Screenshot di Lance Whitney/ZDNET
Non più passare da un tab all’altro
“Che si tratti di un modello locale o basato su cloud, se desideri utilizzare l’IA, riteniamo che dovresti avere la libertà di utilizzare (o meno) gli strumenti che rispondono meglio alle tue esigenze,” ha dichiarato Mozilla a giugno.
“Invece di passare da un tab o un’app all’altra per ottenere assistenza, coloro che hanno optato per questa soluzione avranno la possibilità di accedere al loro servizio di IA preferito direttamente dalla barra laterale di Firefox per riassumere le informazioni, semplificare il linguaggio o testare le loro conoscenze, il tutto senza lasciare la loro pagina web.”
Altri elementi sono disponibili sulla nuova pagina Firefox Labs nelle impostazioni.
L’opzione “Immagine nell’immagine”
Apertura automatica durante il cambio di tab ti permetterà di passare alla modalità immagine nell’immagine per i video attivi quando cambi tab.
Questo significa che puoi visualizzare un video in una piccola finestra PIP su un sito e che la finestra rimarrà sullo schermo anche se passi a un altro tab.
L’opzione “Barra degli indirizzi”
Mostra i risultati mentre digiti l’IME visualizza un IME (Input Method Editor) che ti permetterà di utilizzare la tua tastiera normale per inserire simboli complessi nella barra degli indirizzi, nel campo di ricerca e in altri campi di testo.
Ma non è tutto.
Con Firefox 130, puoi chiedere al browser di tradurre porzioni di testo selezionate in diverse lingue dopo aver tradotto l’intera pagina.
Come assicurarsi che i servizi di intelligenza artificiale non consumino troppa energia?
L’ecosistema francese offre criteri specifici per guidare le scelte dei progettisti e degli utenti di IA. Questi criteri aiutano a valutare e minimizzare l’impatto ambientale delle soluzioni basate sull’intelligenza artificiale.
Tra le raccomandazioni principali, ci sono:
Ottimizzazione degli algoritmi: Utilizzare algoritmi efficienti che richiedono meno risorse per l’elaborazione dei dati.
Scelta di infrastrutture sostenibili: Optare per data center alimentati da fonti di energia rinnovabile.
Efficienza energetica del codice: Scrivere codice che riduce al minimo il consumo di energia durante l’esecuzione.
Monitoraggio e gestione dell’energia: Implementare strumenti per monitorare e ottimizzare il consumo energetico dei sistemi di IA.
Riduzione della complessità dei modelli: Preferire modelli di IA meno complessi e più efficienti che offrono buone prestazioni con minori risorse.
Adottare questi criteri aiuta a garantire che l’uso dell’intelligenza artificiale sia più sostenibile e a ridurre l’impatto ambientale delle tecnologie emergenti.
Le Intelligenze Artificiali sono Grandi Consumatrici di Dati (ANDRIY ONUFRIYENKO / MOMENT RF / GETTY IMAGES)
Redazione di testi, creazione di presentazioni professionali, realizzazione di immagini, video più o meno realistici, o addirittura canzoni pronte all’uso, gli strumenti di intelligenza artificiale (IA) sono ormai diventati parte integrante dei nostri computer. Con interfacce semplificate, questa tecnologia, che risale alla fine degli anni ’50, è ora accessibile attraverso strumenti di uso comune come Google Gemini, ChatPlus e Copilot.
Per funzionare, questi sistemi di IA richiedono enormi quantità di dati, potenza di calcolo elevata e capacità di archiviazione adeguata. Ad esempio, una singola richiesta su ChatPlus consuma 10 volte più energia rispetto a una richiesta effettuata su un motore di ricerca tradizionale. Mentre le industrie storiche (come l’automobile e l’aeronautica) stanno modificando i loro processi produttivi per ridurre le emissioni di carbonio, è fondamentale integrare principi di sostenibilità ambientale fin dalla fase di progettazione dei servizi di IA.
Il bisogno di calcolo per l’IA è aumentato di un milione di volte in sei anni e cresce esponenzialmente ogni anno.
Sundar Pichai, CEO di Google
discorso del 14 maggio 2024
È necessario creare indicatori precisi e quantificabili per misurare l’impatto ecologico globale. L’obiettivo è sviluppare ciò che viene definito IA “frugale”. Fino ad oggi, non esisteva un riferimento internazionale accessibile e praticabile da tutti. Per questo motivo, è importante l’iniziativa francese dell’Ecolab del Commissariato Generale per lo Sviluppo Sostenibile e dell’Associazione Francese di Normalizzazione (AFNOR), che nell’estate del 2024 hanno pubblicato una metodologia operativa per valutare l’impatto ambientale dell’IA.
Questa metodologia è stata elaborata congiuntamente da esperti del mondo accademico, delle imprese, delle associazioni e delle amministrazioni pubbliche. Questo approccio multidisciplinare e imparziale prevede criteri come il consumo di acqua ed energia, le modalità di archiviazione dei dati, la qualità dei dataset, la riutilizzazione di algoritmi già addestrati, e altro ancora. Questi criteri aiuteranno i produttori di IA a misurare e quindi ridurre l’impatto delle loro soluzioni, permettendo loro di mostrare le loro performance in materia e agli acquirenti e utenti di IA di valutare e confrontare i metodi dei loro fornitori.
Un approccio virtuoso per tutte le parti coinvolte.
Puoi distinguere un essere umano da un robot?In un sondaggio, Podcastle, creatore di servizi vocali basati su IA, ha scoperto che due persone su tre non riuscivano a capire se una voce fosse umana o generata dall’intelligenza artificiale. Questo significa che le voci generate dall’IA sono sempre più difficili da distinguere da quelle delle persone reali.
Per le aziende che desiderano fare affidamento sulla generazione di voci artificiali, è promettente. Per il resto di noi, è un po’ inquietante.
La sintesi vocale non è una novità
Molte tecnologie di IA esistono da decenni. Ma nel caso delle voci, la sintesi vocale esiste da secoli. Non è una cosa nuova.
Ad esempio, vi invito a consultare il documento Mechanismus der menschlichen Sprache nebst der Beschreibung seiner sprechenden Maschine, datato 1791. Questo documento spiega come Johann Wolfgang Ritter von Kempelen de Pázmánd abbia utilizzato dei mantici per creare una macchina parlante nell’ambito della sua celebre burla degli automi, il Turco. È così che è nato il termine “turco meccanico”.
Una sintesi vocale computerizzata ha dato al fisico Stephen Hawking la sua voce. Questa voce è stata creata con un computer desktop del 1986, fissato alla sua sedia a rotelle. Non l’ha mai sostituita con qualcosa di più moderno. Ha dichiarato: «La conservo perché mi identifico con essa».
Anche i software di sintesi vocale non sono nuovi. Negli anni ’80, il TI 99/4 integrava la sintesi vocale in alcune cartucce di gioco. E l’Apple II aveva una sintesi vocale.
La maggior parte di queste implementazioni, fino alla metà degli anni 2010, utilizzava fonemi di base per creare la voce sintetica. Tutte le parole possono essere scomposte in circa 24 consonanti e 20 vocali. Questi suoni venivano sintetizzati o registrati, e poi, quando una parola doveva essere “pronunciata”, i fonemi venivano assemblati nell’ordine e riprodotti.
Funzionava. Era affidabile ed efficiente. Ma non suonava come Alexa o Siri.
Le voci AI di oggi
Oggi, grazie alle tecnologie di IA e a una potenza di elaborazione molto maggiore, la sintesi vocale può assomigliare a voci reali. In effetti, la generazione di voci AI di oggi può creare voci che sembrano quelle di persone che conosciamo. Il che può essere una cosa buona o cattiva. Esaminiamo entrambi gli aspetti.
Truffe vocali
A gennaio, un fornitore di servizi vocali ha effettuato migliaia di telefonate fraudolente utilizzando una voce generata dall’IA simile a quella del presidente Joe Biden. La voce diceva agli elettori che se avessero votato alle primarie dello Stato, non sarebbero stati autorizzati a votare alle elezioni generali di novembre. Questo tipo di falsa dichiarazione è illegale e il fornitore di servizi vocali ha accettato di pagare una multa di un milione di dollari allo Stato.
Creazione di contenuti e clonazione vocale
Questo processo, chiamato clonazione vocale, ha applicazioni sia pratiche che malevoli. Ad esempio, il servizio di montaggio video Descript dispone di una funzione di overdub che consente di clonare la tua voce. Poi, se modifichi un video, può sovrapporre la tua voce alle modifiche, in modo che tu non debba tornare indietro e registrare nuovamente i cambiamenti che hai apportato. Il software di Descript sincronizza persino i movimenti delle labbra, così sembra che tu stia dicendo ciò che scrivi nell’editor.
Trascorro troppo tempo a modificare e correggere errori video, quindi capisco l’interesse di questa soluzione. Ma non posso fare a meno di immaginare il male che questa tecnologia può fare. Con la clonazione vocale e l’IA generativa, mamma potrebbe ricevere una chiamata da sua figlia Jane. E la voce sembrerà proprio quella di Jane. Dopo una breve conversazione, mamma scoprirà che Jane è bloccata in Messico e ha bisogno di migliaia di euro per tornare a casa. Era davvero la voce di Jane, quindi mamma ha inviato i soldi. Si scopre che Jane sta benissimo e non sa nulla della truffa di cui sua madre è stata vittima.
Aggiungi anche la sincronizzazione labiale. Ora puoi prevedere un’esplosione di false truffe di rapimento. Perché rischiare di catturare uno studente in viaggio all’estero quando un video completamente falso sarebbe sufficiente? Funziona sempre? No, ma non è necessario. È comunque spaventoso.
Aiuti per l’accessibilità
Ma non tutto è così oscuro. Proprio come la vecchia PC del 1986 ha dato la sua voce al professor Hawking, la moderna generazione vocale basata sull’IA aiuta i pazienti di oggi. NBC ha pubblicato un reportage su una tecnologia sviluppata presso l’Università di Davis che permette a un paziente affetto da sclerosi di recuperare la parola. Il progetto utilizza:
Impianti cerebrali che elaborano i modelli neurali
L’IA che converte questi modelli in parole che il paziente vuole dire
Un generatore di voce AI che parla con la voce reale del paziente.
La voce del paziente affetto da sclerosi è stata clonata a partire da registrazioni della sua voce prima che la malattia gli togliesse la capacità di parlare.
Agenti vocali per il servizio clienti
L’IA nei call center è un argomento molto delicato. In realtà, è l’argomento stesso dei call center a essere delicato. C’è la sensazione di impersonale che si prova quando si deve farsi strada attraverso un albero telefonico e la frustrazione di dover aspettare altri 40 minuti prima di poter parlare con un agente. Poi c’è la frustrazione di trattare con un agente che chiaramente non è formato o che segue uno script che non risolve il tuo problema. C’è anche la frustrazione quando tu e l’agente non riuscite a capirvi a causa della vostra comprensione della lingua. E quante volte sei stato disconnesso perché un agente di primo livello non è riuscito a trasferirti a un responsabile?
Sì, l’IA nei call center può davvero aiutare. Di recente mi sono imbattuto in un’IA mentre dovevo risolvere un problema tecnico. Avevo già aperto un ticket di supporto e ho aspettato una settimana per ottenere una risposta poco utile. L’assistenza vocale non era disponibile. Per frustrazione e un po’ per curiosità, ho deciso finalmente di cliccare sul pulsante “AI Help”. Si è rivelata un’IA molto ben addestrata, in grado di rispondere a domande tecniche piuttosto complesse e di comprendere e implementare le modifiche di configurazione di cui il mio account aveva bisogno. Non c’è stata attesa e il mio problema, che era rimasto irrisolto per più di una settimana, è stato risolto in circa 15 minuti.
Un altro esempio è Fair Square Medicare. Questa società utilizza assistenti vocali per aiutare le persone anziane a scegliere il piano sanitario giusto. L’assicurazione sanitaria è complessa e le scelte non sono evidenti. Le persone anziane spesso si sentono sopraffatte dalle opzioni a loro disposizione. Fair Square ha sviluppato una piattaforma vocale AI generativa basata su GPT-4 che può guidare gli anziani attraverso il processo.
Certo, a volte è piacevole poter parlare con un essere umano. Ma se non riesci a entrare in contatto con un essere umano competente e disponibile, l’IA potrebbe essere una valida alternativa.
Assistenti intelligenti
Poi ci sono gli assistenti intelligenti come Alexa, Google e Siri. Per questi prodotti, la voce è l’elemento centrale del prodotto. Siri, quando è arrivato sul mercato nel 2011, era incredibile per le sue capacità. Alexa, nel 2014, era altrettanto impressionante. Anche se entrambi i prodotti sono evoluti, gli elementi di intelligenza artificiale sembrano essere stagnanti. Nessuno dei due prodotti può competere con le capacità di chat vocale di ChatPlus, soprattutto con ChatPlus Plus e GPT-4. La versione dell’assistente vocale di ChatPlus è straordinaria. Può gestire conversazioni complete, ottenere risposte (anche se a volte inventate) e seguire le linee guida della conversazione. Se la qualità della voce di Alexa (e, in misura minore, di Siri e Google Assistant) è buona, le intonazioni vocali di ChatPlus sono più sfumate.
Ovviamente, il riconoscimento vocale è una delle altre funzioni più notevoli degli assistenti vocali. Questi dispositivi sono dotati di microfoni che consentono loro non solo di distinguere le voci umane dai rumori di fondo, ma anche di ascoltare e interpretare il discorso umano, almeno abbastanza da creare risposte.
Come funziona la generazione vocale AI?
Per fortuna, la maggior parte dei programmatori non ha bisogno di sviluppare la propria tecnologia di generazione vocale da zero. La maggior parte dei grandi attori del cloud offre servizi di generazione vocale AI che funzionano come microservizi o eseguono un’API dalla tua applicazione. Tra questi ci sono Google Cloud Text-to-Speech, Amazon Polly, Azure AI Speech di Microsoft, il framework vocale di Apple, ecc.
In termini di funzionalità, i generatori di voce iniziano con il testo. Questo testo può essere generato da un redattore umano o da un’IA come ChatPlus. Questo testo viene poi convertito in linguaggio umano, ovvero onde sonore che possono essere percepite dall’orecchio umano e dai microfoni. Abbiamo già parlato dei fonemi. Le IA elaborano il testo generato ed eseguono un’analisi fonetica, producendo suoni vocali che rappresentano le parole del testo.
Come vengono addestrate le IA specializzate nella sintesi vocale?
Dal punto di vista dell’addestramento delle IA specializzate, le reti neurali (codice che elabora i modelli di informazione) utilizzano modelli di apprendimento profondo per ingerire ed elaborare enormi set di dati di discorsi umani. Da questi milioni di esempi di discorsi, l’IA può modificare i suoni di base delle parole per riflettere l’intonazione, l’accento e il ritmo, rendendo i suoni più naturali e olistici.
Alcuni generatori di voce AI personalizzano poi il risultato, regolando l’altezza e il tono per rappresentare voci diverse e persino applicando accenti che riflettono il discorso proveniente da una regione particolare. Al momento, l’app per smartphone di ChatPlus non offre questa possibilità, ma puoi chiedere a Siri e Alexa di utilizzare voci diverse o voci provenienti da regioni diverse.
Come funziona il riconoscimento vocale?
Il riconoscimento vocale funziona al contrario. Deve catturare i suoni e convertirli in testo che può poi essere inserito in una tecnologia di elaborazione come ChatPlus o nel back-end di Alexa. Come
L’economia americana sta assistendo a una moria di start-up senza precedenti con il numero di nuove insolvenze di aziende nate come promettenti talenti cresciuto in un anno del 60% e circa 250 fallimenti già constatati tra le aziende sostenute dai fondi di venture capital in cerca di scommesse vincenti nell’economia a stelle e strisce e giunte alla fine del processo di iniezione iniziale di denaro. A riportarlo una ricerca della società di servizi Carta citata dal Financial Times, che spiega come le aziende che avevano ricevuto iniezioni di capitali a partire dal 2021-2022 da parte di fondi di investimento in cerca di ritorni stanno iniziando a soffrire le conseguenze dei mancati ritorni.
Tra queste aziende il Ft cita “il sito web di live streaming Caffeine, che ha raccolto oltre 250 milioni di dollari da investitori tra cui Fox Corp, Andreessen e Sanabil Investments, una divisione del fondo sovrano dell’Arabia Saudita; la start-up sanitaria Olive, valutata l’ultima volta a 4 miliardi di dollari nel 2021; e la società di autotrasporti Convoy, valutata a 3,8 miliardi di dollari nel 2022. La società di gestione di spazi di co-working WeWork, che aveva raccolto circa 16 miliardi di dollari in debiti e azioni da SoftBank e dal suo Vision Fund, ha chiuso a novembre dopo essere diventata quotata nel 2021″.
Molte di queste società hanno ricevuto denaro prima che l’impennata dei tassi d’interesse inaridisse le disponibilità di molti operatori per finanziare le azioni delle nascenti start-up prima che il loro business decollasse. A febbraio era stato profetico un post pubblicato su LinkedIn da Jimmy Song, esperto di bitcoin e investitore, sulla “crisi del venture capital”.
Song notava che “il problema è che c’è troppa domanda. Cioè, ci sono troppi fondi di VC che inseguono troppo poche startup. Di conseguenza, abbiamo avuto il fenomeno delle startup che hanno ottenuto valutazioni folli perché c’era così tanto denaro appena stampato che inseguiva una fornitura piuttosto piccola”. Ne consegue un dato di fatto: “Le startup di oggi sono meno sane di quelle di vent’anni fa perché sono state coccolate da troppi soldi.”. Ma, ha notato Song, “i tassi di interesse più elevati più di recente hanno significato che c’è stata meno stampa di denaro e quindi meno denaro è fluito nelle società di venture capital”.
Con 4 milioni di persone che negli Usa lavorano nelle aziende sostenute dai venture capitalist, ricorda il Ft, il dato da tenere d’occhio è tanto quello osservabile a ritroso quanto quello in prospettiva: che ne sarà dei dipendenti delle aziende finanziate con finanziamenti imponenti nel campo dell’intelligenza artificiale tra il 2023 e il 2024? Che prospettive si apriranno per ulteriori scommesse a rischio se il costo del denaro, calando, favorirà investimenti a debito e altissima leva potenziale e rischio? Come mediare tra una situazione che vede molte aziende tecnologiche cercare miliardi di dollari per i loro algoritmi e la più grande rivoluzione tecnologica in atto far fare soldi, per ora, solo ai costruttori di hardware come Nvidia?
In passato le start-up erano portatrici di grandi idee capaci di scalare il mercato con la speranza di esplodere con il sistema del venture capital e diventare solide. Ora il rischio che emerge è che siano diventate, in larga parte, cacciatrici di finanziamenti desiderose di mettersi solo in una seconda fase alla prova del mercato. Con tutti i rischi del caso qualora a scoppiare fosse una bolla di start-up legate all’Ia. Al cui confronto l’attuale fase di crisi apparirebbe una parentesi serena.
Vuoi ricevere le nostre newsletter?
Dacci ancora un minuto del tuo tempo!
Se l’articolo che hai appena letto ti è piaciuto, domandati: se non l’avessi letto qui, avrei potuto leggerlo altrove? Se non ci fosse InsideOver, quante guerre dimenticate dai media rimarrebbero tali? Quante riflessioni sul mondo che ti circonda non potresti fare? Lavoriamo tutti i giorni per fornirti reportage e approfondimenti di qualità in maniera totalmente gratuita. Ma il tipo di giornalismo che facciamo è tutt’altro che “a buon mercato”. Se pensi che valga la pena di incoraggiarci e sostenerci, fallo ora.
Immagini generate dall’intelligenza artificiale di Grok.
La dinamica è ben nota: non appena un programma di intelligenza artificiale generativa viene messo online, gli utenti cercano subito di farlo deragliare. Questo è esattamente ciò che è accaduto quando xAI, l’azienda di Elon Musk dedicata all’intelligenza artificiale, ha lanciato, martedì 13 agosto, la versione 2.0 del suo software Grok. Accessibile ai possessori di un abbonamento “premium” al social network X, questo chatbot permette di generare testo, ma ora anche immagini. Da allora, gli utenti sono riusciti, con una facilità sconcertante, a fargli produrre immagini violente e altri deepfake.Una rappresentazione di Elon Musk in un liceo, armato, circondato da cadaveri di adolescenti; Barack Obama intento a consumare cocaina; Donald Trump e Kamala Harris in costume da bagno… Sono tutti contenuti che altri generatori di immagini per il grande pubblico generalmente vietano: Dall-E (OpenAI), in particolare, rifiuta le rappresentazioni di personalità pubbliche o di attività illegali.
Questi software vietano anche, in teoria, le violazioni del diritto d’autore. Eppure, Grok genera facilmente contenuti che raffigurano Topolino, Mario o SpongeBob, ad esempio, o addirittura tutti e tre insieme, come in un’immagine in cui condividono cannabis con Elon Musk. Sebbene sembri altrettanto facile usare Grok per generare immagini di personaggi in biancheria intima, il software rifiuta tuttavia di produrre contenuti pornografici.
Elon Musk contro le IA “woke”
Grok non è il primo sistema di IA a consentire la creazione di questo tipo di immagini. Tuttavia, i principali strumenti commerciali, dotati di restrizioni severe, richiedono generalmente stratagemmi più o meno complessi per aggirarle.
Il caso di Grok è particolare: Elon Musk ha sempre criticato i programmi di intelligenza artificiale generativa dei suoi concorrenti, sottoposti, a suo dire, al politicamente corretto e all’agenda “woke”. Aveva ferocemente criticato Google a febbraio, quando il suo software Gemini aveva raffigurato persone nere come soldati tedeschi della seconda guerra mondiale o i padri fondatori degli Stati Uniti. “Il virus woke sta uccidendo la civiltà occidentale”, aveva reagito, accusando Google di sviluppare programmi “razzisti e anticivilizzazione”.
Mentre lavorava al lancio di Grok, aveva confidato al canale americano Fox News di voler sviluppare un chatbot che cercasse prima di tutto la “verità”. Al suo lancio, a novembre, Grok, che allora poteva solo generare testo, non integrava quasi nessuna delle protezioni contro gli abusi divenute standard presso i suoi concorrenti.
Rispondendo a un messaggio che elogiava l’aspetto “non censurato” di Grok 2.0 e il suo presunto rispetto della “libertà di espressione”, Elon Musk ha dichiarato mercoledì: “Grok è l’IA più divertente del mondo!”, scatenando i commenti degli utenti fan del multimiliardario, che hanno moltiplicato le immagini generate da Grok che lo raffigurano in pose eroiche accanto a Donald Trump, di cui sostiene la campagna.
Non è certo che questa nuova versione di Grok divertirà i regolatori, a pochi mesi dalle elezioni presidenziali americane, e mentre il social network X è sotto inchiesta europea: la Commissione Europea sospetta che non stia rispettando i suoi obblighi in materia di moderazione dei contenuti illegali e di disinformazione.
A fine luglio, gli utenti del social network X non potevano rifiutare l’uso dei loro dati personali da parte di Grok tramite uno smartphone. KIRILL KUDRYAVTSEV / AFP
Questa politica di condivisione dei dati, molto criticata e attivata di default nelle impostazioni degli utenti senza richiedere alcun consenso, era stata scoperta alla fine di luglio. Subito dopo, molti difensori della privacy online avevano allertato le autorità europee riguardo a una possibile violazione del Regolamento Generale sulla Protezione dei Dati (RGPD).
La DPC, l’equivalente irlandese della Commissione nazionale per l’informatica e le libertà (CNIL), si era quindi occupata della questione, dato che la sede europea di X si trova a Dublino. Attivando una “richiesta urgente”, un meccanismo previsto dal RGPD che consente alle autorità di protezione dei dati di ordinare la sospensione, la limitazione o l’interdizione di un trattamento dei dati, la DPC ha infine raggiunto un accordo con X.
Otto denunce in corso in Europa
Nel suo comunicato, la DPC annuncia che l’utilizzo dei dati personali degli utenti europei per addestrare il chatbot Grok, sviluppato da xAI, un’altra azienda di Elon Musk, è stato sospeso il 1° agosto. Era stato introdotto discretamente il 7 maggio.
La DPC, che lavora in collaborazione con i regolatori europei, “continua a esaminare in che misura il trattamento di questi dati sia conforme al RGPD”, ha precisato Des Hogan, il suo presidente. “Continueremo a collaborare con la DPC riguardo a Grok e ad altri temi legati all’intelligenza artificiale, come facciamo dall’anno scorso”, ha dichiarato il social network X in un comunicato venerdì.
Ma la società di Elon Musk non è ancora fuori pericolo. La piattaforma è oggetto di denunce in otto paesi europei per il suo utilizzo “illegale” dei dati personali degli utenti in questo programma di intelligenza artificiale, secondo l’associazione NOYB. X “non ha mai informato proattivamente i suoi utenti che i loro dati personali erano utilizzati per addestrare l’IA”, ha scritto questa settimana l’ONG viennese, acerrima nemica dei giganti della tecnologia, che aveva già costretto Meta a fare marcia indietro su una questione simile a giugno.
Meta, da parte sua, ha dovuto sospendere a giugno il suo progetto di utilizzo dei dati personali degli utenti in un programma di intelligenza artificiale, dopo denunce in 11 paesi europei. L’associazione NOYB aveva chiesto alle autorità di intervenire “con urgenza” per impedire l’attuazione di questa nuova politica di riservatezza, accusando Meta di voler utilizzare tutte le informazioni raccolte dai suoi miliardi di utenti dal 2007 per sfruttarle in una “tecnologia sperimentale di IA senza alcun limite”.
L’intelligenza artificiale può essere utilizzata per generare testo, immagini, ma anche video. Una funzionalità che l’azienda madre di TikTok, ByteDance, desidera sviluppare.
TikTok // Fonte: Pixabay
TikTok potrebbe presto offrire uno strumento per la creazione di video generati dall’intelligenza artificiale. ByteDance si sta lanciando con uno strumento che consente di creare video e immagini a partire da prompt.
**Sulle tracce di OpenAI**
Nel febbraio 2024, OpenAI, la società dietro ChatPlus e lo strumento di generazione di immagini Dall-E, ha presentato il suo modello di generazione di video, Sora. Questo strumento ha suscitato grande interesse, spingendo altre aziende, come ByteDance, a posizionarsi in questo campo.
La casa madre di TikTok intende rispondere con il suo strumento Jimeng AI a una crescente domanda di creazione di contenuti video tramite IA in Cina. L’applicazione è stata lanciata su Android il 31 luglio ed è ora disponibile anche sull’App Store, ma solo in Cina.
Per ora, sappiamo solo che gli utenti potranno creare video a partire da testo, senza però avere specifiche precise sulla lunghezza e la risoluzione di questi video. Si può tuttavia immaginare che questi saranno ottimizzati per i social media come TikTok.
**Immagini e video**
Jimeng AI ha una carta importante da giocare nel campo della generazione di contenuti, poiché, a differenza di OpenAI e Sora, Jimeng è in grado di generare sia immagini che video.
L’applicazione offre la possibilità di creare fino a 2050 immagini o 168 video generati dall’IA al mese, a seconda del piano di abbonamento scelto. I piani variano da 8 euro per un abbonamento mensile a 84 euro per un abbonamento annuale (questi prezzi sono stabiliti sulla base della conversione da yuan a euro senza considerare eventuali tasse applicabili).
Al momento, non abbiamo informazioni sulla base di dati utilizzata per generare questi video. La vicinanza con TikTok solleva domande, e ci si potrebbe chiedere se i video prodotti sulla piattaforma sociale potrebbero alimentare questa IA.
Una pratica già vista in atto presso altri gruppi come Meta. A maggio scorso, Meta ha annunciato l’intenzione di utilizzare i nostri post su Facebook e Instagram per migliorare l’apprendimento della sua intelligenza artificiale.